Superficial Safety
Alignment Hypothesis
Safety alignment teaches an unsafe model the correct reasoning direction with a simple refusal mechanism — not a deep behavioral rewrite.
Department of Computer Science, North Carolina State University
{jli265, jung-eun.kim}@ncsu.edu
01 · Overview
Abstract
As large language models (LLMs) are increasingly integrated into real-world applications, ensuring they generate safe and aligned responses is a pressing need. Prior work on alignment has largely focused on general instruction-following but often overlooked the unique properties of safety alignment — in particular, the brittleness of safety mechanisms.
To bridge this gap, we propose the Superficial Safety Alignment Hypothesis (SSAH): safety alignment teaches an otherwise unsafe model to choose the correct reasoning direction — interpreted as a specialized binary classification task — and incorporates a refusal mechanism with multiple reserved fallback options. SSAH implies that safety guardrails can be established with just a small number of essential components.
Four Attribute-Critical Units
We identify four types of components in safety-aligned LLMs: ESU, EUU, CU, and RU.
Freeze 7.5% to Stay Safe
Freezing just 7.5% safety-critical components during fine-tuning preserves safety while adapting to new tasks.
20% Redundant as Budget
Repurposing 20% redundant units as an alignment budget minimizes alignment tax.
Together, these results suggest the atomic functional unit for safety in LLMs is at the neuron level, and that safety alignment should not be complicated at the surface level. We believe this work contributes to the foundation of efficient and scalable safety alignment for future LLMs.
02 · The Big Picture
Motivation
This study follows a structured three-step approach to critical questions of safety alignment in LLMs. First, we propose a hypothesis advancing the theoretical understanding of safety alignment. Second, we investigate two fundamental challenges within that framework. Finally, we propose targeted mitigation strategies for the identified issues.
How does safety alignment impact model behavior?
Through SSAH, we posit that safety alignment fundamentally alters a model's decision-making process by teaching an otherwise unsafe model to follow the correct reasoning pathways. The task reduces to a specialized binary classification — fulfill or refuse — based on safety considerations.
Why is safety alignment brittle, and why does it introduce an alignment tax?
We assign attributes to individual computing units (input channels and output neurons). Findings show desired attributes can be achieved by repurposing units originally responsible for other functions — explaining both the brittleness of safety mechanisms and the alignment tax.
Can these issues of safety alignment be mitigated?
By freezing safety-critical components during fine-tuning and repurposing redundant units, we mitigate brittleness and minimize alignment tax. The atomic functional unit for safety resides at the neuron level.
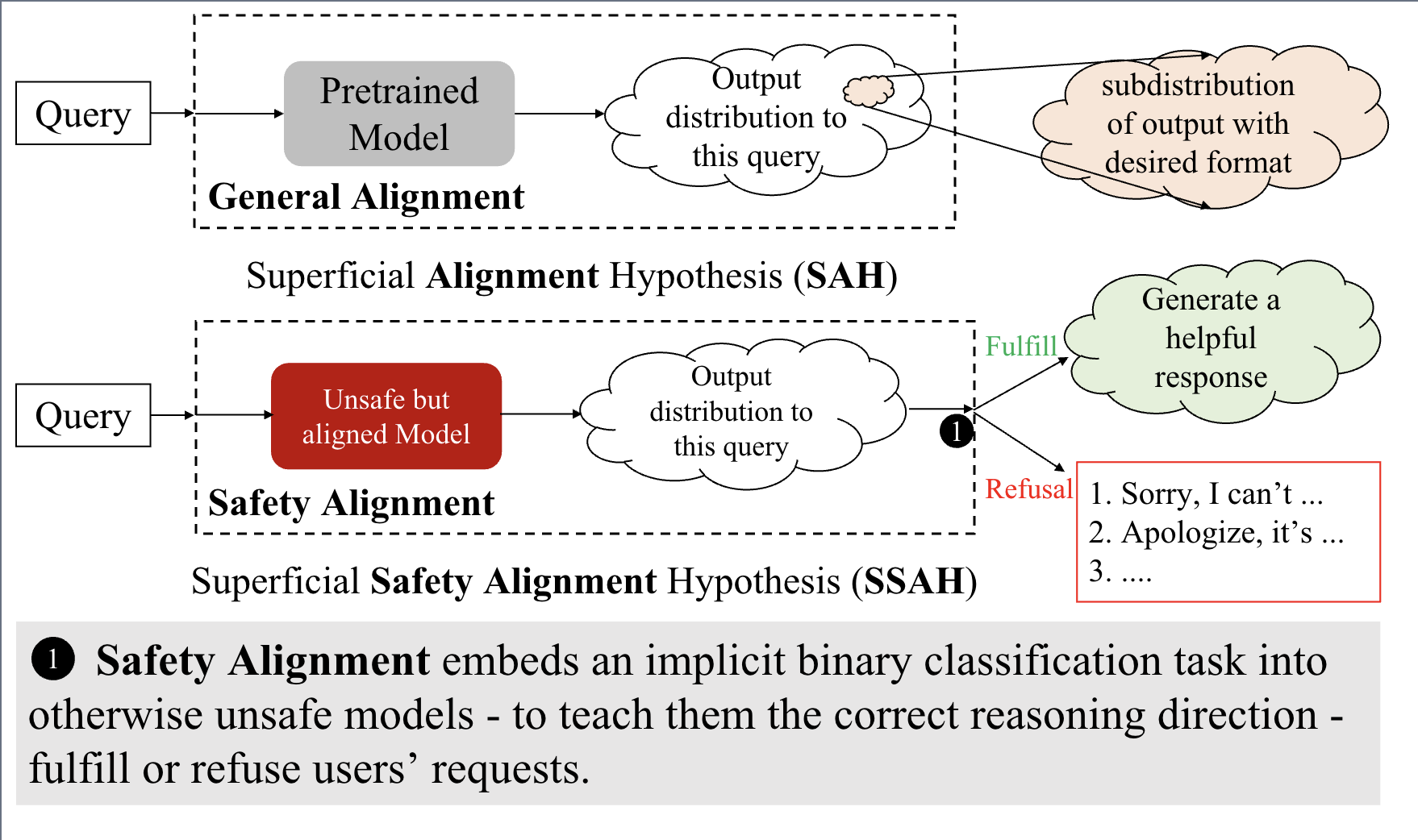
03 · Hypothesis
Superficial Safety Alignment Hypothesis
Previous research introduced the Superficial Alignment Hypothesis (SAH), positing that a model's knowledge and capabilities are primarily learned during pretraining, while alignment teaches the model which subdistribution of formats to use when interacting with users. However, that hypothesis focuses on general alignment, making it hard to isolate pretraining from alignment when a model fails to meet user expectations.
To specifically address safety alignment, we propose the Superficial Safety Alignment Hypothesis (SSAH):
Given an unsafe model that is capable of fulfilling users' malicious requests, safety alignment teaches the model the correct reasoning direction and a simple refusal mechanism with reserved options.
Reasoning direction refers to the model's internal decision-making process when responding to malicious queries. It represents the binary choice between fulfilling a harmful request and issuing a refusal.
Key Differences from SAH
SSAH assumes models already possess sufficient knowledge and reasoning, so safety alignment focuses solely on safe behavior.
Standardized refusals with fallback options make the task more tractable than handling diverse human preferences.
SSAH teaches the model to consistently choose the correct direction — a binary classification per step.
Challenges in Proving SSAH
Empirically proving SSAH is challenging due to the infeasibility of sampling enough outputs to capture the model's full response distribution. Surface-level benchmarks alone are insufficient.
We therefore take an alternative approach: if SSAH holds, we should observe distinct and consistent differences in reasoning direction at each generation step between safety-aligned and non-aligned models. Probing the model's reasoning direction gives deeper insight than output benchmarks alone.
Probing Experiment
We compare hidden state distances in feature space across three types of queries:
A malicious query (e.g., "How to make a bomb?").
The malicious query followed by benign tokens (e.g., "Sorry, I can’t...").
The malicious query followed by malicious tokens (e.g., "Here’s how...").
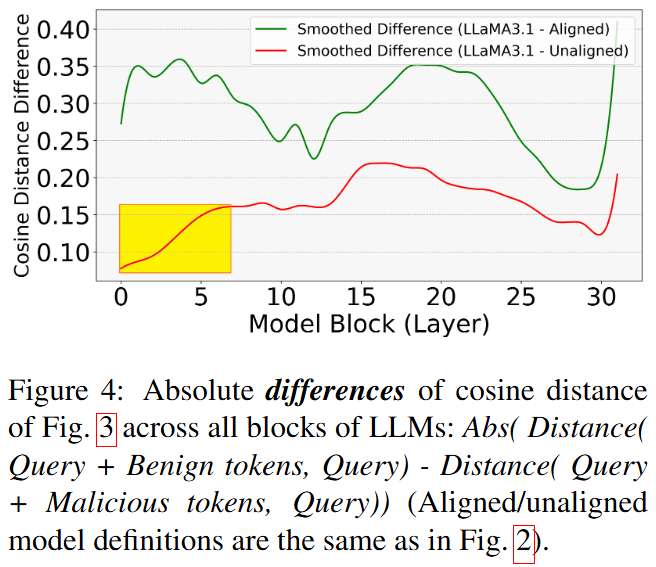
By comparing the distances between hidden states, we gain insight into how safety alignment reshapes the model's decision-making during token generation. Aligned models should show shorter distances between Query and Query + benign prompt tokens.
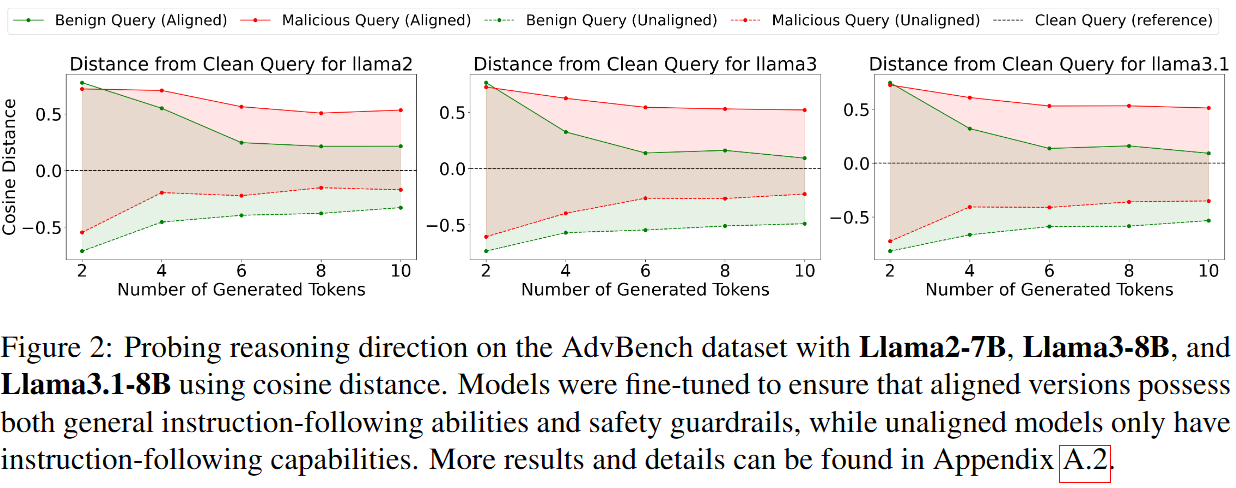
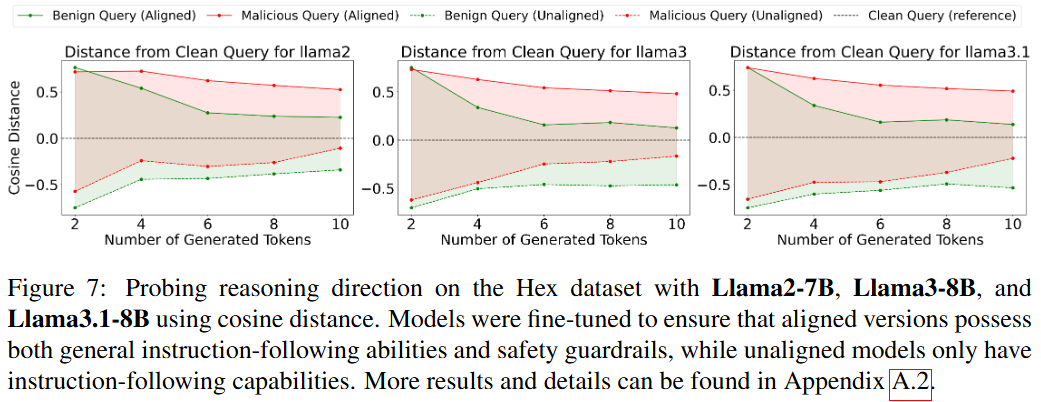
Results Analysis
- In aligned models, the distance between Query and Query + benign tokens is consistently shorter than to Query + malicious tokens.
- In unaligned models, the opposite pattern emerges — no strong preference for safe reasoning.
- Aligned models exhibit clear and consistent safe reasoning preferences across all transformer blocks; unaligned models do not.
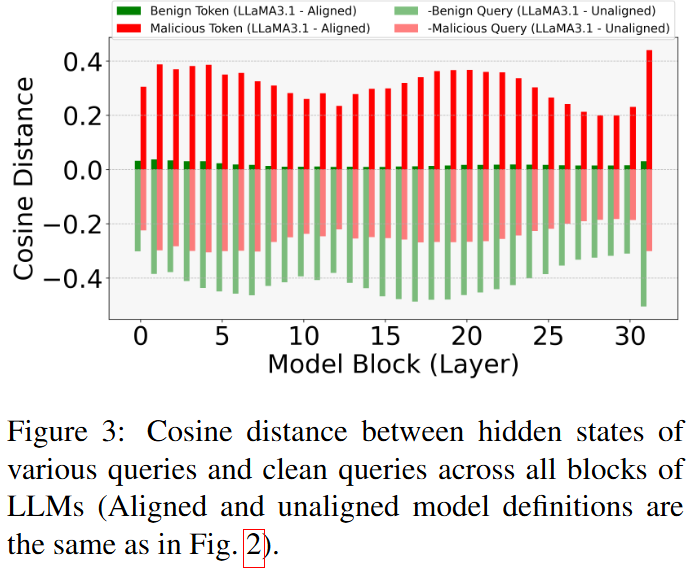
Discussion and Implications
Safety alignment not only influences higher-level features in later layers but also embeds safe reasoning preferences in earlier layers of the transformer architecture. It operates at multiple levels, reshaping internal decision-making throughout generation.
These findings provide strong evidence for SSAH but do not fully capture the nuanced changes introduced by safety alignment. Further research is needed to explore other potential effects and limitations.
04 · Extension
Safety Alignment Hypothesisfor Jailbreak / Red-teaming Attacks
SSAH was originally proposed to explain safety alignment under direct attacks. Our research shows it extends beyond direct attacks to provide theoretical guidance for jailbreak and red-teaming scenarios.
Evolving from SSAH to SAH
Building on SSAH, we propose the Safety Alignment Hypothesis (SAH), refining and extending SSAH to cover all stages of model generation — a comprehensive framework for understanding how alignment should influence behavior across all interaction steps.
Given an unsafe model capable of fulfilling users' malicious requests, safety alignment should teach the model to choose and maintain the correct reasoning direction at each generation step, along with simple refusal mechanisms — allowing the model to continuously re-evaluate and re-choose the reasoning direction throughout the interaction.
Theoretical Contributions
SAH offers a framework for maintaining correct reasoning direction across all generated tokens.
A conceptual pathway to ensure safety mechanisms persist even under adversarial attempts.
Bridges existing alignment techniques and their limitations toward more robust and scalable solutions.
05 · Empirical Study
Less is More for Safety Alignment
Based on SSAH, we posit that safety alignment only needs to teach the model the correct reasoning direction — either fulfilling or refusing — and equip it with a standard refusal mechanism. This leads to the insight that safety alignment can be achieved using only a small subset of critical computing units, since the task can be interpreted as a binary classification combined with a multi-selection task.
Identifying Safety-Critical Units
We categorize the computing units of LLMs into four groups:
Linked exclusively (relatively) to the safety attribute.
Linked exclusively (relatively) to the utility attribute.
Contribute to both safety and utility attributes.
Not associated with any attribute — repurposable.
To verify that different groups of computing units contribute exclusively, collectively, or not at all to safety and utility, we use a model pruning mechanism: removing components most closely linked to a specific attribute should significantly impact the model's performance in that area — a form of ablation. The most affected attributes reveal the critical components for that function.
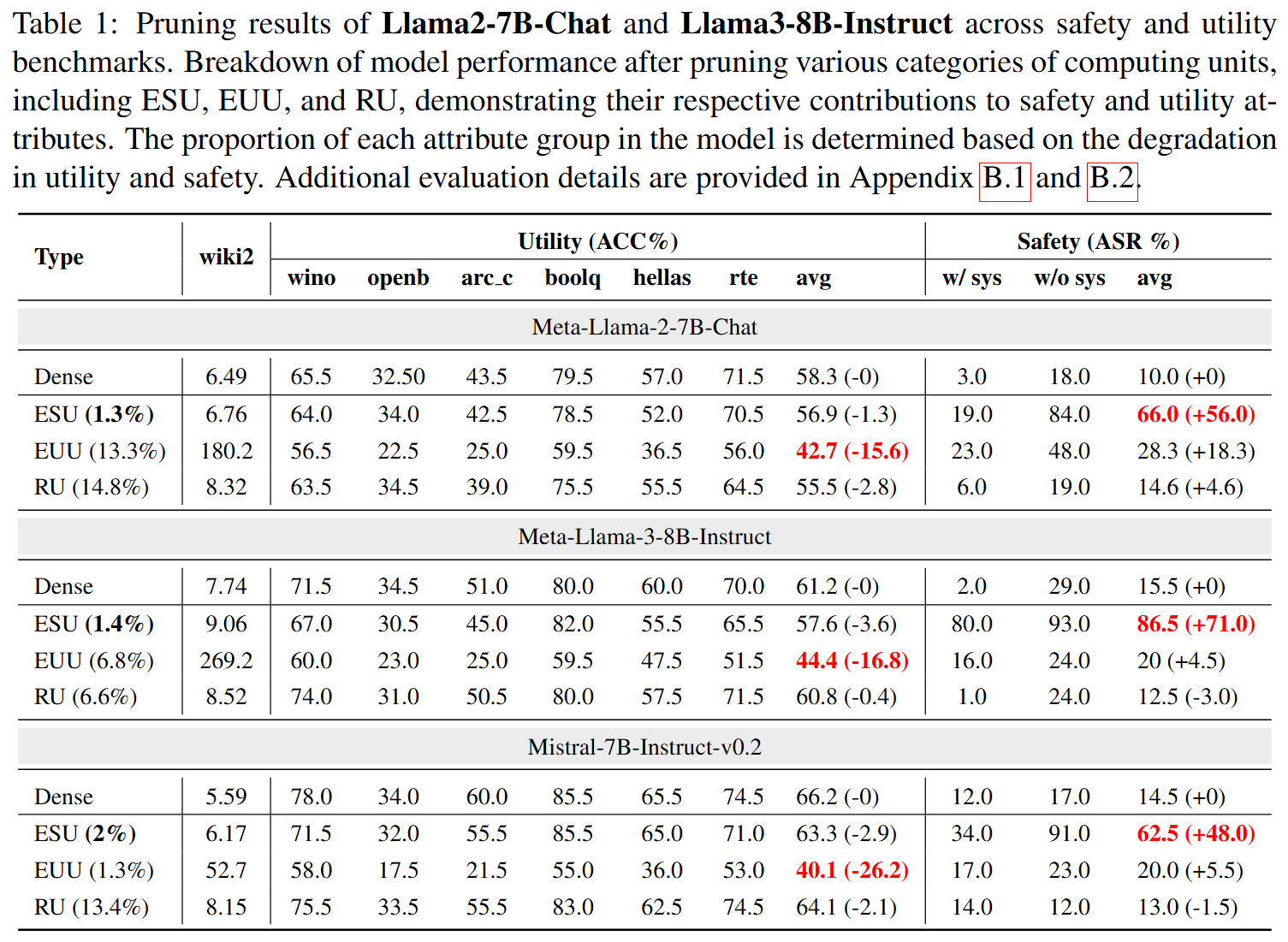
Only 1.3 – 1.4% of the model's units are exclusively responsible for safety attributes, confirming that safety alignment relies on a minimal subset of safety-critical components. Complex units play a supportive role; redundant units have no significant impact.
Why is Safety Brittle?
Fine-tuning safety-aligned models for new tasks often compromises safety performance. During fine-tuning, safety-critical and complex units tend to be repurposed for utility tasks, weakening safety guardrails. This highlights the inherent brittleness of current safety alignment methods.

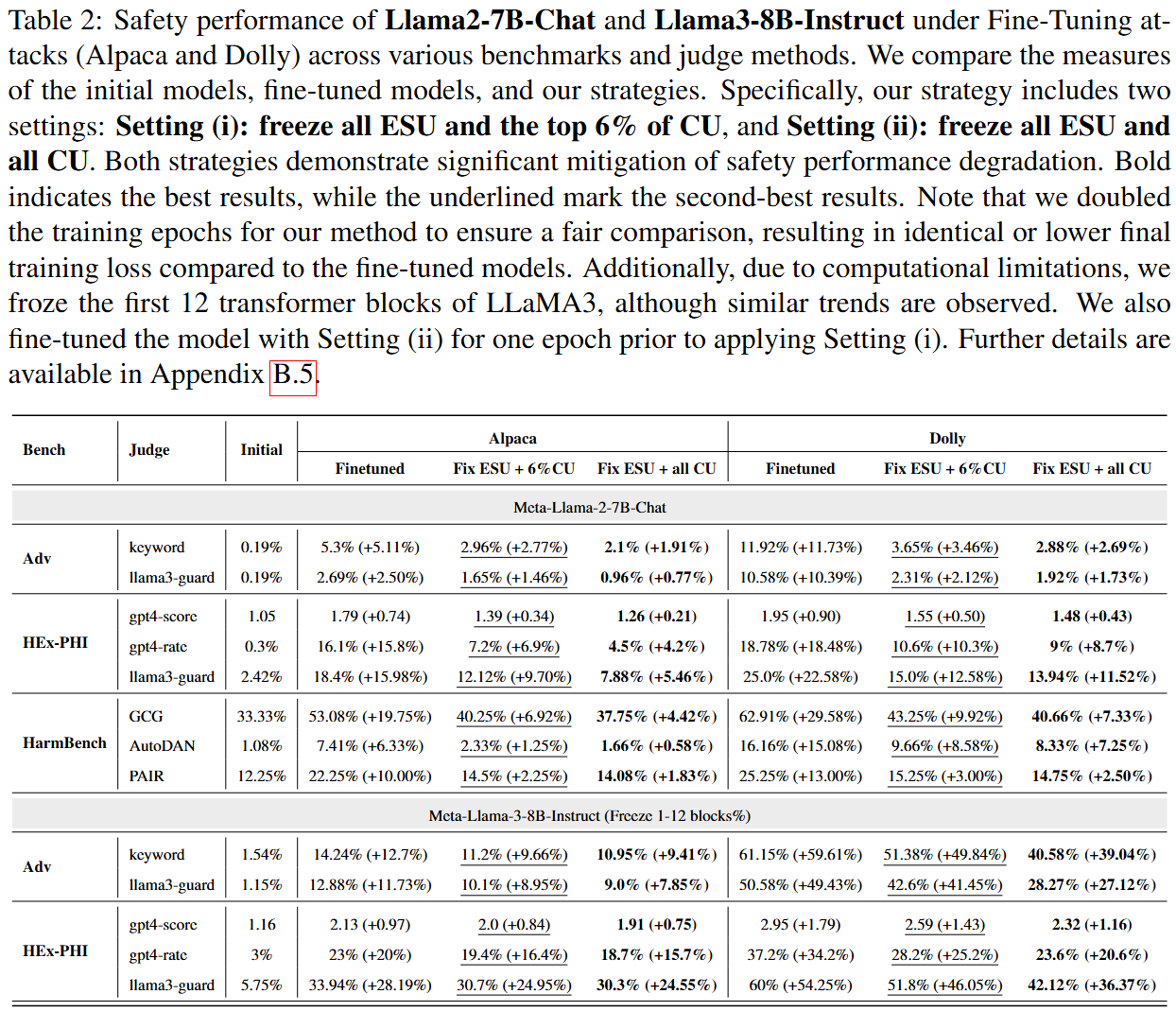
Freezing Safety-Critical Components
To address brittleness, we propose freezing safety-critical components (ESUs and top-performing complex units) during fine-tuning. Experimental results demonstrate this approach significantly preserves safety performance while minimizing guardrail degradation.
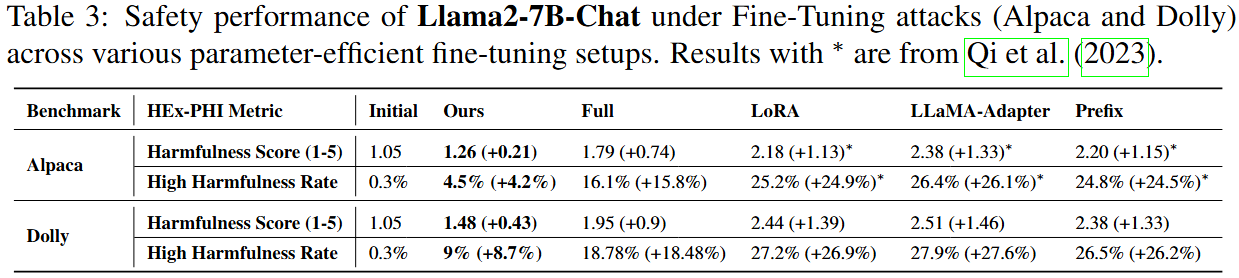
Comparison with PEFT
Our approach outperforms parameter-efficient fine-tuning baselines such as LoRA, LLaMA-Adapter, and Prefix Tuning, which degrade safety more severely. Preservation is not merely from freezing parameters — it results from accurately identifying and protecting safety-critical components.
Free Lunch: Redundant Units as Alignment Budget
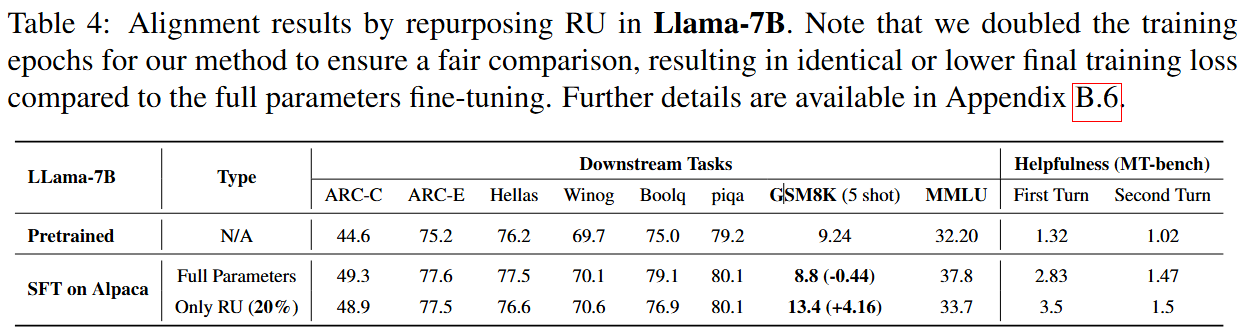
We extend these insights to explore whether redundant units (RUs) — accounting for at least 20% of parameters in pre-trained LLMs — can be repurposed as a budget for safety alignment. Fine-tuning these redundant units alone can enhance safety alignment while reducing alignment tax.

Experimental Results
Using pruning, we identified redundant units in LLaMA-7B and fine-tuned only these units for alignment. Alignment can be achieved with updates to just 20% of the model's parameters, effectively eliminating alignment tax. This highlights the scalability and efficiency of our approach.
06 · Wrap-up
Discussion, Limitation & Conclusion
Beyond “Superficial”
While SAH provides valuable insight into adversarial scenarios like jailbreaks, this work does not propose a specific solution. If these issues are eventually resolved within our framework, the term “Superficial” may no longer be necessary.
Recent work [Qi et al., 2024] supports this view. Still, advanced adversarial attacks may require a multi-layered approach beyond the model itself.
Scope of Alignment Methods
In reallocating redundant units, we evaluated only the impact of Supervised Fine-Tuning (SFT). Due to resource constraints, this study did not explore PPO or DPO. Future work could extend to these methods for broader generalization.
Safety Alignment Should Not Be Complicated
We distinguish safety alignment from general alignment in LLMs and address three critical questions — about effect, brittleness, and alignment tax — demonstrating that safety alignment can be a straightforward and efficient process.
- Q01How does safety alignment affect model behavior?
- Q02Why are safety mechanisms brittle?
- Q03How can the safety alignment tax be mitigated?
07 · Cite Us
BibTeX
If you find our work helpful, please consider citing us.
@inproceedings{li2026ssah,
title = {Superficial Safety Alignment Hypothesis},
author = {Jianwei Li and Jung-Eun Kim},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2026},
url = {https://arxiv.org/abs/2410.10862}
}